

A unified interface to time-series forecasting in Python
When people ask me what kind of data science one can do at Heidelberg Materials, there is a lot of prejudice on the whole IT setup within a 100+ years old construction company. I am more than happy to share an announcement to prove the contrary. Meet HCrystalBall – Heidelberg Materials' first open-source package that allows scalable, production-ready forecasting of time-series data like predicting daily demand for cement across plants and products.
How does it work?
HCrystalBall library has two main pillars, that make it very easy to use, yet receive high-quality results.
Wrapper part
The lower-level part wraps the most popular python time-series libraries to allow for unified communication with them (there are fbprophet, arima/autoarima, exponential smoothing from statsmodels, and (t)bats, just to name a few). You can imagine wrappers as adapters, that enable UK or US chargers to work within the EU power grid.
Without HCrystalBall, you would need to implement many data transformations to get from historical training data to the future forecast in the required form.
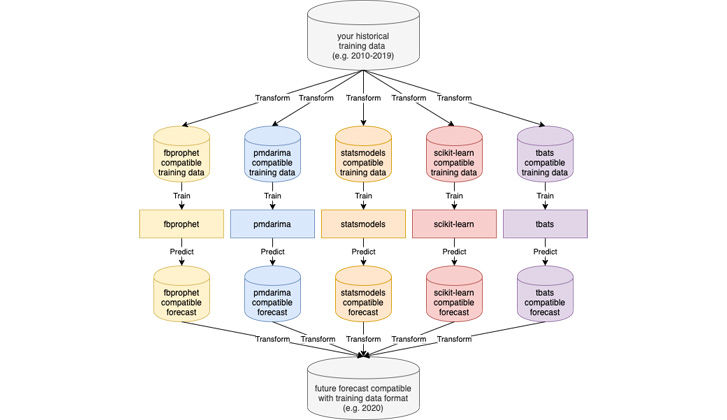
While HCrystalBall wrappers bring all of this to just one interface you need to conform and prepare your data from/to.
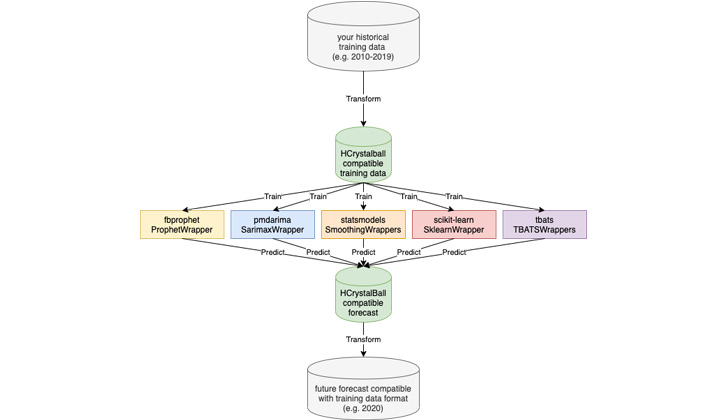
Besides fewer data transformations needed, this enables the model selection part or combining models into more complex, hierarchical structures. It can also be used stand-alone.
Model selection part
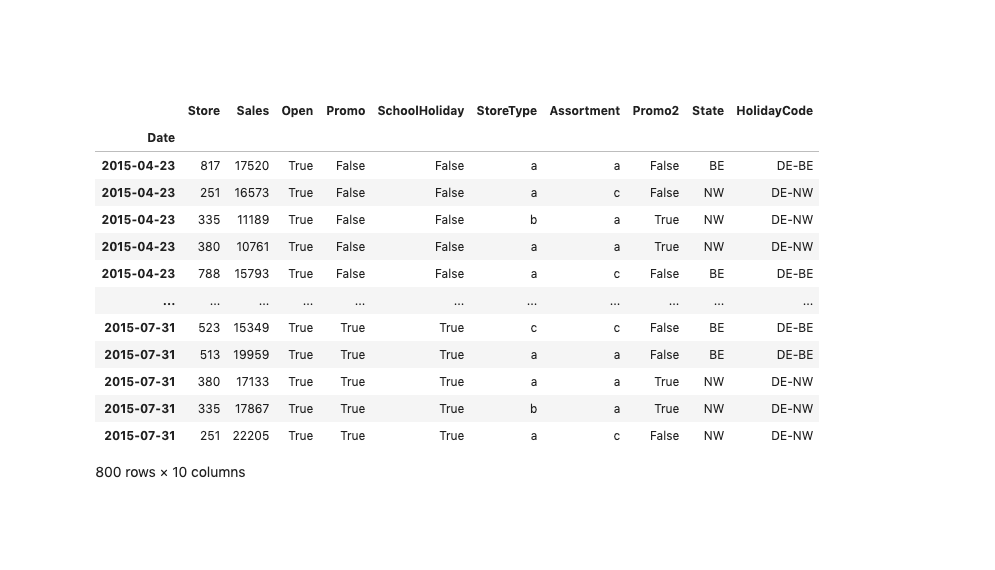
In most of our use-cases, our data look similar to the image below - we have columns, that slice the data (here for example State and Store), information about region's ISO code (from which we can take into account the effect of public holidays) and the time-series we want to forecast to the future (here column `Sales` - the volume of the sales within each store for several days).
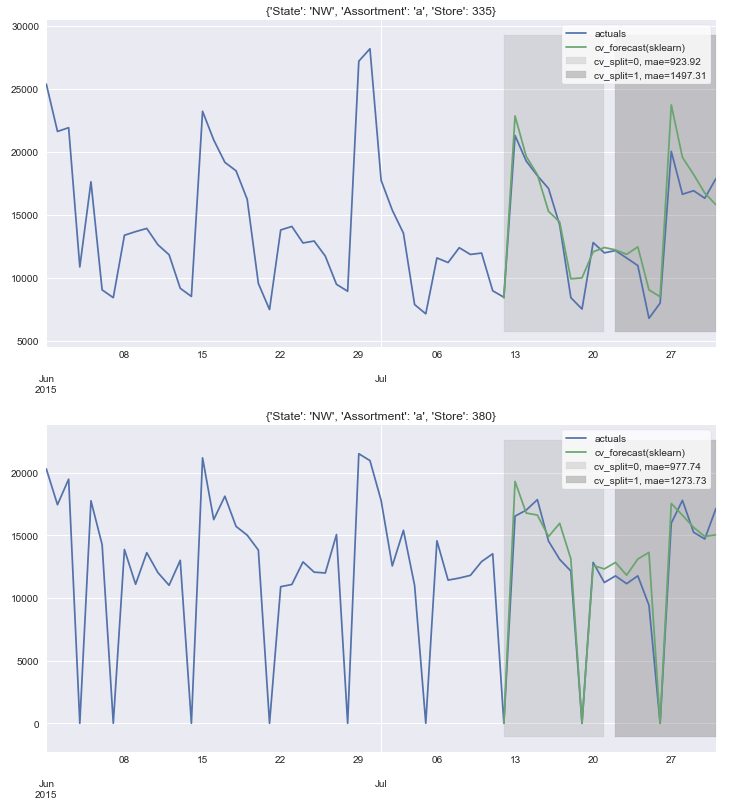
This data acts as an input to the model selection, which is defined by several parameters (like for how many days ahead you want your predictions or which models to use). Such form can be easily digested to a Python from Excel-like files using the Pandas library. When the model selection is finished, you'll receive a rich representation of the statistics around the selected models throughout your data slices and also metrics showing why the selected model is the best one. Our charts will give you intuition on the accuracy of the predictions.
Even without a programming background, it is really easy to try this on binder (give it some time or few page refreshes, once done, clicking to the run icon is enough to see the results you are creating).
Usage
HCrystalBall has proven its value in many places by being the main building block of the majority of our use-cases throughout business lines and departments (logistics, cement, or ready-mix concrete to name a few) and we strongly believe the wider community can benefit from using it.
Try it!
The easiest way to try HCrystalBall is going through examples in the pre-built environment (no need to install anything). If you don’t need the interactivity, pre-executed notebooks are part of our docs in the example section. Check the installation instruction on how to set up your local environment. We've also published a more technically oriented blog post with code examples. Interested in code or contribution? Visit the GitHub repository.
Brought to you with care by the Data Science Team at Heidelberg Materials
